Please define the positive impact your project will have on the wider Cardano community
The Cardano ecosystem has seen remarkable growth in tooling and resources, lowering entry barriers for DApp and smart contract development. Despite these advancements, due to computational constraints around on-chain smart contracts, the need for low-level control to optimize performance remains a critical challenge. Plutarch stands out by offering granular control over contract logic. However, lower-level control introduces a trade-off: on one hand, experienced developers are able to craft highly optimized contracts, reducing resource usage and operational costs. On the other hand, the complexity of working with these tools can deter less experienced developers, thus creating barriers to adoption. As a result, many projects develop their own performant libraries, adding to the ecosystem's fragmentation. Our proposed on-chain standard library aims to bridge this gap by offering a robust performance-oriented foundation on top of Plutarch and providing accessible abstractions/utilities to a wider audience. Note that the targeted audience is not limited to Plutarch developers as we will also provide Aiken bindings. However, compiled UPLC code can in theory be imported and used within any on-chain framework. By centralizing and optimizing the library, we reduce redundancy across projects and streamline development processes within the ecosystem.
The subsequent sections outline common performance challenges and new features to be included in the library:
High Assurance
Given the current state of the ecosystem, there is great burden upon DApp developers to ensure the assurance of their smart contracts. However, underlying standard library functions in many cases, are not extensively tested or formally verified. The proposed standard library will be designed with great attention to security and ease of use. The library will be comprehensively tested using property-based testing and formal verification techniques to assert robustness of all library functionalities.
Unrolling recursive calls
Due to the absence of native support for recursion in UPLC, all recursive functions (e.g. pall, pelemAt, etc) rely on the Y-combinator to facilitate recursion. While this method is theoretically robust, it is inefficient in practice as recursive functions are passed repeatedly along the recursion chain. Most of the time, the required number of recursive calls are predictable according to the application context. We therefore propose to unroll recursive calls prior to the UPLC generation. This approach enables a strategic balance between script size (e.g. unrolling of tail calls when traversing a list) and execution unit consumption (i.e., recursion expansion at runtime), potentially yielding substantial performance improvements.
Converting between Scott and Builtin Data
A significant opportunity for performance enhancement lies in the trade-off between using Scott-encoded data versus builtin data structures in smart contract logic. Scott encoding generally offers efficiency advantages when handling complex data structures. However, this efficiency comes with a cost: serializing and de-serializing data into Scott encoding can incur substantial performance penalties. PlutusTx adopts this approach by default, i.e., encoding all builtin structures into Scott encoding. In contrast, tools like Aiken exclusively operate over builtin structures, which might appear to optimize performance by avoiding data structure conversions. However, solely using builtin structures carries drawbacks especially when they are fully traversed or manipulated multiple times. Plutarch provides developers with granular control over these two operating levels, but this can be challenging for those with limited experience in profiling on-chain scripts. To aid developers in making informed choices regarding the appropriate level of abstraction, the standard library will include both utilities and comprehensive documentation.
Early failure
Haskell developers commonly use sum-type data structures such as Maybe and Either to represent function return types that might fail or result in unexpected states. While these patterns are considered idiomatic in Haskell development, they are often viewed as anti-patterns in the development of on-chain smart contracts for two primary reasons:
-
Additional Overheads: These structures add overhead to the existing domain data structures. In a resource-constrained environment, such overheads can significantly increase both script size and memory usage.
-
Failure Propagation: Failures are typically propagated through the execution logic of the contract until they are handled at a higher level. This propagation can occur during critical operations such as searches, look-ups, and contract validation logic. It is thus considered a best practice in on-chain development to terminate execution as early as possible when errors are detected. This approach not only reduces execution unit costs, especially in complex contracts, but also minimizes potential security vulnerabilities that could arise from improper handling of failures.
As an example, consider the pfind function below:
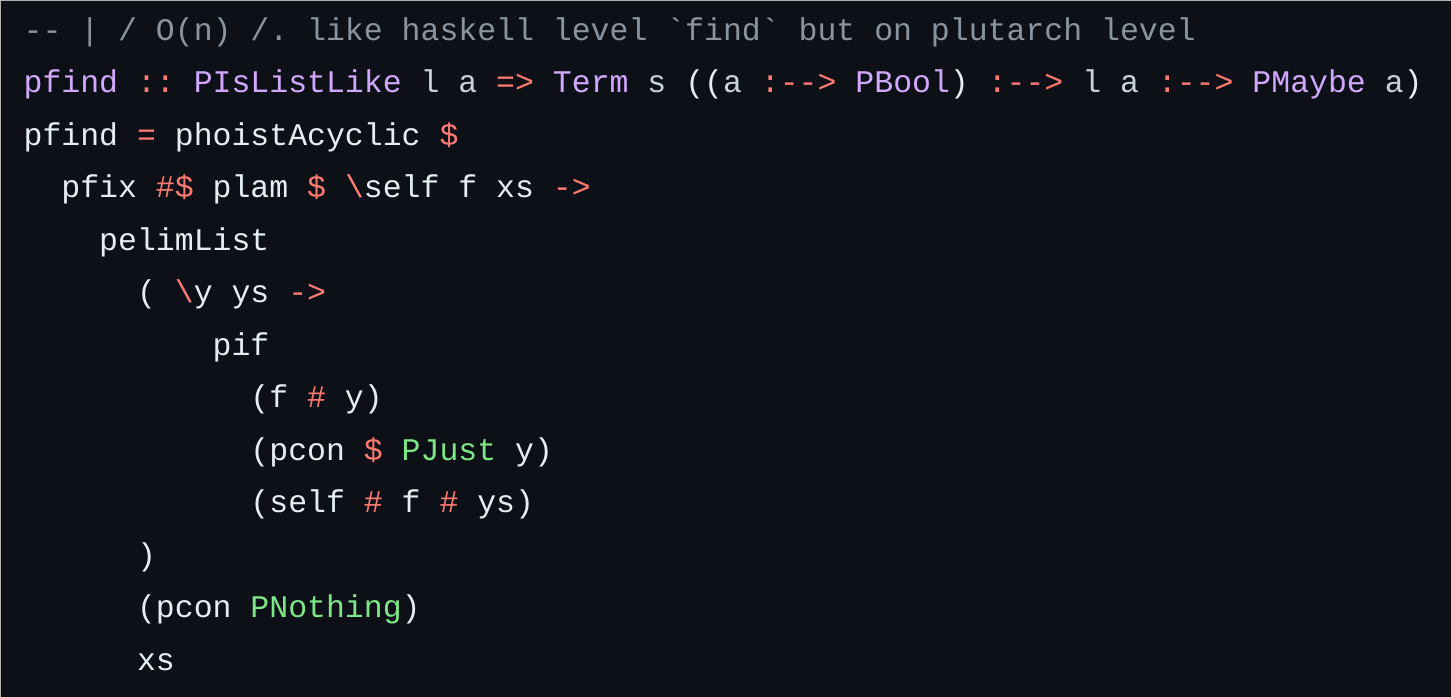
This function searches for an element in a list that satisfies a specific predicate f. In practice, pfind might be used to locate an input within a transaction that contains a certain NFT, triggering additional logic. Therefore, it would be more efficient to immediately terminate the execution if the condition is not met. In doing so, this will save on execution units and reduce potential security vulnerabilities that may follow from not adequately addressing the PNothing case.
Also note that the recursive function accepts an argument f, which remains constant throughout the entire recursive execution. In such cases, it would be more efficient to move f to an outer lambda such that it only gets applied once instead of being applied at each recursive call. This is all to illustrate that the current standard library is not sufficient for production use-cases.

